#include <iostream>
int zeta_search(int n, int r, int c) {
if (n == 1) {
return r * 2 + c;
} else if (n > 1) {
return 4 * zeta_search(n - 1, r / 2, c / 2) + zeta_search(1, r % 2, c % 2);
} else {
return -1;
}
}
int main() {
int n, r, c;
std::cin.tie(nullptr);
std::ios::sync_with_stdio(false);
std::cin >> n >> r >> c;
std::cout << zeta_search(n, r, c) << '\n';
return 0;
}
큐(Queue)는 선입선출(first-in first-out, FIFO) 방식으로 자료형을 삽입하고 제거할 수 있는 자료구조이다. queue라는 단어는 "(무엇을 기다리는 사람들의) 줄" 이라는 의미도 있으므로, 흔히 표를 구입할 때 "먼저 줄 선 사람이 먼저 구입하고 빠지는 것" 비유하곤 한다.
버스는 먼저 줄 선 사람부터(first-in) 먼저 탄다(first-out)
구현해야 하는 명령 다섯가지
push X: 정수 X를 큐에 넣는 연산이다.
pop: 큐에서 가장 앞에 있는 정수를 빼고, 그 수를 출력한다. 만약 큐에 들어있는 정수가 없는 경우에는 -1을 출력한다.
size: 큐에 들어있는 정수의 개수를 출력한다.
empty: 큐가 비어있으면 1, 아니면 0을 출력한다.
front: 큐의 가장 앞에 있는 정수를 출력한다. 만약 큐에 들어있는 정수가 없는 경우에는 -1을 출력한다.
back: 큐의 가장 뒤에 있는 정수를 출력한다. 만약 큐에 들어있는 정수가 없는 경우에는 -1을 출력한다.
아이디어/참고
큐의 추상 자료형(ADT)은 다음과 같다. (출처: Data Structures & Algorithms in C++, 2nd Edition)
Algorithm size():
return n
Algorithm empty():
return (n = 0)
Algorithm front():
if empty() then
throw QueueEmpty exception
return Q[f]
Algorithm dequeue():
if empty() then
throw QueueEmpty exception
f←(f+1) mod N
n = n−1
Algorithm enqueue(e):
if size() = N then
throw QueueFull exception
Q[r]←e
r←(r+1) mod N
n = n+1
여기서 dequeue는 큐에서 자료를 제거하는 것이므로 pop에 대응, enqueue는 큐에 자료를 삽입하는 것이므로 push에 대응한다. 또한 가장 뒤에 있는 요소를 반환하는 back이 없으므로 이를 추가해주면 될 듯 하다.
front와 rear를 굳이 mod N으로 해주는 이유는, front나 back의 위치가 큐의 배열의 크기(N)를 넘어가면 안되므로 다시 처음으로 돌아가기 위함이다.
명령어 입력
이 문제 역시 명령어를 입력하여 정수만을 저장할 수 있으면 되는 것이므로, 명령어 입력에 대해 대략 수도코드를 짜보았다.
int n 선언
문자열 command 선언
Queue q 선언
n 입력받음
for i=0, i<n, i++
cmd 입력받음
if cmd = size then
q.size() 출력
else if cmd = empty then
q.empty() 출력
else if cmd = front then
q.front() 출력
else if cmd = back then
q.front() 출력
else if cmd = push then
int x 선언하고 입력받기
q.push() 실행
else if cmd = pop then
q.pop() 출력
스택(Stack)은 후입선출(Last-in first-out, LIFO) 방식으로 자료를 삽입하거나 제거할 수 있는 자료구조 중 하나이다.
이번 문제는 이 스택을 구현하고 이를 명령어로 실행하는 것을 요구한다.
출처: 위키백과
구현해야 하는 명령 다섯가지
push X: 정수 X를 스택에 넣는 연산이다.
pop: 스택에서 가장 위에 있는 정수를 빼고, 그 수를 출력한다. 만약 스택에 들어있는 정수가 없는 경우에는 -1을 출력한다.
size: 스택에 들어있는 정수의 개수를 출력한다.
empty: 스택이 비어있으면 1, 아니면 0을 출력한다.
top: 스택의 가장 위에 있는 정수를 출력한다. 만약 스택에 들어있는 정수가 없는 경우에는 -1을 출력한다.
아이디어/참고
스택의 추상 자료형(ADT)은 다음과 같다. (출처: Data Structures & Algorithms in C++, 2nd Edition)
Algorithm size():
return t+1
Algorithm empty():
return (t<0)
Algorithm top():
if empty() then
throw StackEmpty exception
return S[t]
Algorithm push(e):
if size() = N then
throw StackFull exception
t←t+1
S[t]←e
Algorithm pop():
if empty() then
throw StackEmpty exception
t←t−1
이를 클래스로 만들면 될 것 같다. 그리고 해당 문제는 정수만 구현하면 된다.
명령어 입력
이 문제는 단순 스택의 함수를 호출하는 것이 아닌 명령어가 입력으로 주어지면 호출하는 방식이므로, 명령어를 받아들이고 조건문을 통하여 명령어가 맞으면 해당 명령을 실행하는 식으로 코드를 짜면 될 것 같다.
int n 선언
string command 선언
Stack s 선언
n 입력받음
for i=0, i<n, i++
cmd 입력받음
if cmd = size then
s.size() 출력
else if cmd = empty then
s.empty() 출력
else if cmd = top then
s.top() 출력
else if cmd = push then
int x 선언하고 입력받기
s.push() 실행
else if cmd = pop then
s.pop() 출력
#include <iostream>
#include <string>
using namespace std;
#define CAPACITY 1000
class CustomStack {
private:
int* stack_array;
int capacity;
int t;
public:
CustomStack(int cap){
stack_array = new int[cap];
capacity = cap;
t = -1;
}
int size() const{
return (t+1);
}
int empty() const{
if (t<0)
return 1;
else
return 0;
}
int top() const{
if (empty() == 1) return -1;
return stack_array[t];
}
void push(int x){
t++;
stack_array[t] = x;
}
int pop(){
if (empty() == 1) return -1;
int temp = stack_array[t];
t--;
return temp;
}
};
int main()
{
int n;
string cmd;
CustomStack s(CAPACITY);
cin >> n;
for (int i=0; i<n; i++){
cin >> cmd;
if (cmd == "size"){
cout << s.size() << '\n';
}
else if (cmd == "empty"){
cout << s.empty() << '\n';
}
else if (cmd == "top"){
cout << s.top() << '\n';
}
else if (cmd == "push"){
int x;
cin >> x;
s.push(x);
}
else if (cmd == "pop"){
cout << s.pop() << '\n';
}
}
return 0;
}
두 번째 답안
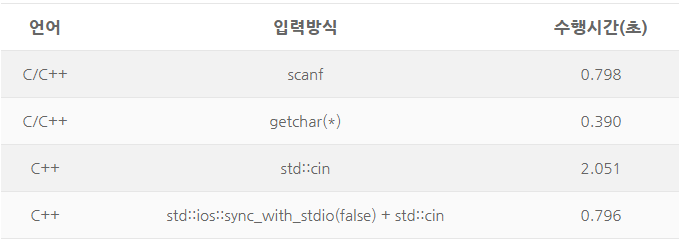
- 문제를 풀다보니 실행시간이 312ms나 나올 게 있나..? 하는 생각이 들어서 찾아봤더니, std::cin과 std::cout이 printf와 scanf보다 속도가 엄청 느리다는 이야기가 있었다. 다른 사람들이 C++로 작성한 것을 참고해보니 전부 printf와 scanf를 사용하였다.
(0, 0) 좌표에서 입력받은 값 n의 2승(=n^2) 부터 시작하여 행(row)의 값이 증가하는 방향으로 시작
테스트 환경
- OS: Windows 10
- IDE: Visual Studio Code
- 컴파일러: Visual C++
첫 번째 답
- 코드 용량: 1988KB
- 실행 시간: 156ms
- 아이디어
실행 순서
- 답안
#include <iostream>
using namespace std;
void snail(int n, int find)
{
int l = n;
int value = n * n;
int row = -1;
int col = 0;
int dir = 1;
int x, y;
int** arr;
arr = new int* [n];
for(int i=0; i<n; i++) arr[i] = new int[n];
while (l > 0){
for (int i=0; i<l; i++){
row = row + dir;
arr[row][col] = value;
if (value == find){
x = col + 1;
y = row + 1;
}
value--;
}
l--;
for (int i=0; i<l; i++){
col = col + dir;
arr[row][col] = value;
if (value == find){
x = col + 1;
y = row + 1;
}
value--;
}
dir = dir * (-1);
}
for(int i=0; i<n * n; i++){
int r = i / n;
int c = i % n;
cout << arr[r][c] << " ";
if((i % n) == n - 1) cout << endl;
}
cout << y << " " << x << endl;
for(int i=0; i<n; i++) delete[] arr[i];
delete[] arr;
}
int main()
{
int n, find;
cin >> n >> find;
snail(n, find);
return 0;
}
두 번째 답
첫 번째 코드의 경우 아이디어를 따왔던 게시글에 있는 코드와 유사하게 짰음.
이번엔 꼭지점에 도달할 경우 방향을 바꾸는 방식으로 진행.
- 코드 용량: 1988KB
- 실행 시간: 156ms
- 아이디어
첫 열에 대해 값 입력.꼭지점에 도달하고, 두 번째 열이 첫번째가 되도록 함.꼭지점에 도달하고, 네 번째 행이 마지막이 되도록 함.
- 답안
#include <iostream>
using namespace std;
void snail(int n, int find)
{
int row = 0, col = 0;
int value = n*n;
int rfirst = 0, cfirst = 0;
int rlast = n-1, clast = n-1;
int x, y;
int** arr;
arr = new int* [n];
for(int i=0; i<n; i++) arr[i] = new int[n];
while (value > 0){
arr[row][col] = value;
if (value == find){
x = col + 1;
y = row + 1;
}
value--;
if (row < rlast && col == cfirst){
row++;
if (row == rlast) cfirst++;
}
else if (row == rlast && col < clast){
col++;
if (col == clast) rlast--;
}
else if (row > rfirst && col == clast){
row--;
if (row == rfirst) clast--;
}
else if (row == rfirst && col > cfirst){
col--;
if (col == cfirst) rfirst++;
}
}
for(int i=0; i<n * n; i++){
int r = i / n;
int c = i % n;
cout << arr[r][c] << " ";
if((i % n) == n - 1) cout << endl;
}
cout << y << " " << x << endl;
for(int i=0; i<n; i++) delete[] arr[i];
delete[] arr;
}
int main()
{
int n, find;
cin >> n >> find;
snail(n, find);
return 0;
}
#include <string>
#include <iostream>
using namespace std;
bool isGroupWord(string str) {
int i = 0;
while (i < str.length() - 1) {
// 인접한 두 문자가 같은 문자일 경우 스킵
if (str.at(i) == str.at(i + 1)) {
i++;
} else {
for (int j = i + 1; j < str.length(); j++) {
// 연속해서 나타나지 않는 경우 false 반환
if (str.at(i) == str.at(j))
return false;
}
i++;
}
}
return true;
}
int main() {
int n, count;
string* str;
// 단어 개수 입력받고 str에 배열 동적할당
cin >> n;
str = new string[n];
// 단어 입력
for (int i = 0; i < n; i++) {
cin >> str[i];
}
count = 0;
// 단어가 그룹 단어이면 count를 1 증가시킴
for (int i = 0; i < n; i++) {
if (isGroupWord(str[i])) count++;
}
cout << count << endl;
delete[] str;
return 0;
}
시간복잡도를 최적화한 풀이
- 이미 등장한 알파벳인지를 판단하는 불 타입 배열 선언
- 제출한 답: C++로 작성, 1988KB
- 결과: 정답
#include <string>
#include <iostream>
using namespace std;
const char LITTLE_A = 'a';
bool isGroupWord(string str) {
// 단어 중복을 체크할 불 배열 선언
bool* wordCheck = new bool[26]{ false, };
wordCheck[str.at(0) - LITTLE_A] = true;
for (int i = 1; i < str.length(); i++) {
// 이미 등장한 알파벳인지 체크
if (!wordCheck[str.at(i) - LITTLE_A])
wordCheck[str.at(i) - LITTLE_A] = true;
// 만약 이미 등장한 알파벳이라면 앞자리의 알파벳과 동일한지 체크
else
if (str.at(i) != str.at(i - 1)) return false;
}
delete[] wordCheck;
return true;
}
int main() {
int n, count;
string* str;
// 단어 개수 입력받고 str에 배열 동적할당
cin >> n;
str = new string[n];
// 단어 입력
for (int i = 0; i < n; i++) {
cin >> str[i];
}
count = 0;
// 단어가 그룹 단어이면 count를 1 증가시킴
for (int i = 0; i < n; i++) {
if (isGroupWord(str[i])) count++;
}
cout << count << endl;
delete[] str;
return 0;
}
#include <iostream>
using namespace std;
void swap(int &a, int &b) {
int temp;
temp = a;
a = b;
b = temp;
}
void sort(int *arr, int n) {
int min;
for (int i = 0; i < n - 1; i++) {
min = i;
for (int j = i; j < n; j++) {
if (arr[j] < arr[min]) {
min = j;
}
};
swap(arr[i], arr[min]);
}
}
int main() {
int n, *arr;
cin >> n;
arr = new int[n];
for (int i = 0; i < n; i++) {
cin >> arr[i];
}
sort(arr, n);
for (int i = 0; i < n; i++) {
cout << arr[i] << endl;
}
delete[] arr;
return 0;
}