내가 본격적으로 집을 떠나 자취로 하기로 결정한 것은 지금의 회사(랩이오사)에 입사를 하고 나서 불과 사흘이 지났을 때였다. 본래 나는 집에서 통근을 하는 것을 염두에 두었다. 왕복 4시간에 달하는 긴 거리지만 회사는 내 출신 모교의 바로 앞에 있는 건물에 위치해 있고 4년 내내 다녔던 길이기 때문에 충분히 할 수 있을 거라고 생각했다. 자취를 하는 것도 물론 생각 안해본 것은 아니나, 부담스러운 월세방보다는 고시원이나 쉐어하우스를 알아볼까 하는 생각이 들었다.
입사 사흘 째에 집으로 돌아가 침대에 누워 모교의 커뮤니티 사이트를 살펴보던 중 불과 40분 전에 올라온 글을 보았다. 월세방을 양도한다는 내용이었다. 글쓴이의 계약기간이 나의 첫 계약기간과 정확히 일치하고, 사진으로 보이는 것에 비해 월세가 꽤 저렴했다. 그때 뭔가에 홀린 듯 글쓴이에게 글에 적혀있는 연락처로 바로 문의를 드렸다.
다음 날 아침 출근하는 도중 집을 보러 와도 된다는 연락을 받았다. 당일 저녁에 약속을 잡고 회사에서 퇴근하자마자 집을 보러 갔다. 여자분의 방이었기 때문에 서랍을 열어보는 등의 행동은 할 수 없었지만 전체적으로 혼자 살기에는 꽤 깔끔하고 넓은 방이었다. 집에 돌아가면서 큰 고민에 빠졌다. 예정에도 없던 자취를 해야하나 싶으면서도 이 곳에서 내 첫 커리어를 시작했으면 좋겠다는 생각이 들었다.
돌아가는 버스 안에서 전화로 부모님을 설득했다. 그리고 나서 글쓴이에게 주말에 계약을 하고 싶다는 의견을 전달했고, 다음 날 바로 부동산에 가서 임대차 계약을 했다. 이삿날은 그 다음 날인 일요일로 결정했다.
자바에서의 클래스는 멤버로 속성을 표현하는 필드(field)와 동작을 표현하는 메소드(method)를 가집니다. 이 글에서 소개할 개념은 바로 클래스의 일원인 메소드(method)입니다. 자바의 메소드는 다른 언어에서 이야기하는 함수(function)과 같은 개념으로 볼 수 있습니다. 그러나 자바는 객체지향 언어이므로, 메소드를 클래스 내에서 작성하고 사용합니다.
메소드란 무엇인가?
메소드는 어떠한 특정 작업을 수행하기 위한 명령문의 집합입니다. 메소드를 사용하기 위해서는 정의가 필요하고, 또 정의한 메소드를 호출하는 작업이 필요합니다. 정의란 메소드가 실행하는 특정 작업을 작성하는 것이고, 호출이란 정의된 메소드를 실행하는 것입니다.
메소드를 왜 쓰는가?
메소드를 정의하고 호출하여 사용할 때 얻을 수 있는 이점은 다음과 같습니다.
불필요하게 중복되는 코드의 반복적인 프로그래밍을 피할 수 있습니다. 이렇게 함으로서 코드의 가독성이 좋아집니다.
코드에 문제가 생길 경우 문제가 되는 메소드만 수정하면 됨으로써 유지보수에 도움이 됩니다.
우리가 흔히 알고있는 System.out.println() 역시 메소드로서 미리 정의된 메소드를 호출하는 것입니다.
메소드의 구조와 정의
자바의 메소드 구조를 설명하기 위해 다음과 같은 예시를 준비했습니다.
자바의 메소드는 크게 메소드 헤더와 메소드 바디로 나뉩니다. 이는 선언부와 실행 블록으로도 불립니다. 각각에는 다음과 같은 정보가 들어갑니다.
메소드 헤더(선언부)
수정자(Modifier) 수정자 혹은 제어자라고 하며, 해당 메소드의 메모리 할당 속성, 접근 권한을 등을 결정합니다. 위의 예시의 경우 public이므로 해당 메소드가 소속한 클래스를 인스턴스화하여 자바 프로젝트 어느 곳에서든 호출이 가능한 메소드이다.
반환값 자료형(Return Value Type) 메소드가 호출의 결과를 반환할 때의 반환값의 자료형을 결정합니다. 메소드에 따라 반환값이 있을 수도 있고 없을 수도 있습니다. 그러나 자료형이 명시되어 있다면 반드시 호출한 곳으로 돌려줄 값이 있어야 합니다. 반환할 값이 없다면 void로 명시합니다.
메소드 이름(Method Name) 해당 메소드를 식별할 수 있는 이름입니다. 자바에서는 다음과 같은 사항에 주의하면 됩니다.
숫자로 시작하면 안 되며, $와 _를 제외한 특수 문자를 사용하지 말아야 한다.
관례적으로 메소드명은 소문자로 작성하고, 서로 다른 단어가 혼합된 이름이라면 뒤이어 오는 단어의 첫머리 글자는 대문자로 작성한다. (이 규칙은 camelCase라는 명칭으로도 불린다.)
매개변수(Parameters) 메소드 호출 시, 메소드가 기능을 수행할 때 필요한 값을 전달하기 위해 필요한 변수입니다. 메소드를 호출할 때 전달된 값은 인자(Argument)라고 합니다. 전달할 값이 없다면 빈칸으로 놔 둡니다.
메소드 바디(실행 블록)
반환값(Return Value) 메소드가 기능을 수행한 후 반환하는 값입니다. 반환값의 자료형이 void일 경우 return은 생략됩니다. (반드시 생략되는 것은 아닙니다.)
메소드의 동작
위의 내용을 미루어 보아 메소드의 동작은 다음과 같습니다.
미리 정의한 메소드의 이름으로 메소드를 호출하고, 호출할 때 입력값으로 인자를 전달합니다.
매개변수가 정의되지 않았을 경우 빈칸으로 둡니다. 예시) sum();
매개변수를 통하여 입력값을 받고, 미리 정의한 내용대로 메소드의 기능을 수행한 후 결과값을 return으로 반환합니다.
반환값의 자료형이 void일 경우 return을 생략할 수 있습니다.
public void main() {
int a = 1;
int b = 2;
int result = sum(a, b); // 해당 위치에서 호출, 변수 a와 b를 인자로 전달
System.out.println(result); // 3
}
public int sum(int a, int b) {
return a+b; // 메소드를 수행하고 a+b라는 결과값을 반환
}
메소드의 책임
소프트웨어 전문가 로버트 C. 마틴은 저서 클린 코드에서 함수를 정의할 때에 있어서 다음과 같은 충고를 남겼습니다.
함수는 한 가지를 해야한다. 그 한 가지를 잘 해야 한다. 그 한 가지만을 해야 한다.
그러면서 함수를 만드는 규칙은 작게, 더 작게 만드는 것이라고 표현한다.
하나의 메소드가 너무 많은 역할을 하면 안되고, 일관적인 추상화 수준을 유지하여 하나의 역할만을 해야한다고 한다.
문제
다음 문제를 읽고 답안을 작성하세요.
두 정수 a, b를 인자로 받고, 두 정수를 곱한 결과를 정수로 반환하는 메소드 이름이 multiple인 메소드를 Java 코드로 정의하세요. (단, 접근자는 public)
두 정수 a, b를 인자로 받고, 두 정수의 크기를 비교하여 a가 더 크면 -1, b가 더 크면 1, 서로 같으면 0을 반환하는, 메소드 이름이 compare인 메소드를 Java 코드로 정의하세요. (단, 접근자는 public)
#include <iostream>
int zeta_search(int n, int r, int c) {
if (n == 1) {
return r * 2 + c;
} else if (n > 1) {
return 4 * zeta_search(n - 1, r / 2, c / 2) + zeta_search(1, r % 2, c % 2);
} else {
return -1;
}
}
int main() {
int n, r, c;
std::cin.tie(nullptr);
std::ios::sync_with_stdio(false);
std::cin >> n >> r >> c;
std::cout << zeta_search(n, r, c) << '\n';
return 0;
}
큐(Queue)는 선입선출(first-in first-out, FIFO) 방식으로 자료형을 삽입하고 제거할 수 있는 자료구조이다. queue라는 단어는 "(무엇을 기다리는 사람들의) 줄" 이라는 의미도 있으므로, 흔히 표를 구입할 때 "먼저 줄 선 사람이 먼저 구입하고 빠지는 것" 비유하곤 한다.
버스는 먼저 줄 선 사람부터(first-in) 먼저 탄다(first-out)
구현해야 하는 명령 다섯가지
push X: 정수 X를 큐에 넣는 연산이다.
pop: 큐에서 가장 앞에 있는 정수를 빼고, 그 수를 출력한다. 만약 큐에 들어있는 정수가 없는 경우에는 -1을 출력한다.
size: 큐에 들어있는 정수의 개수를 출력한다.
empty: 큐가 비어있으면 1, 아니면 0을 출력한다.
front: 큐의 가장 앞에 있는 정수를 출력한다. 만약 큐에 들어있는 정수가 없는 경우에는 -1을 출력한다.
back: 큐의 가장 뒤에 있는 정수를 출력한다. 만약 큐에 들어있는 정수가 없는 경우에는 -1을 출력한다.
아이디어/참고
큐의 추상 자료형(ADT)은 다음과 같다. (출처: Data Structures & Algorithms in C++, 2nd Edition)
Algorithm size():
return n
Algorithm empty():
return (n = 0)
Algorithm front():
if empty() then
throw QueueEmpty exception
return Q[f]
Algorithm dequeue():
if empty() then
throw QueueEmpty exception
f←(f+1) mod N
n = n−1
Algorithm enqueue(e):
if size() = N then
throw QueueFull exception
Q[r]←e
r←(r+1) mod N
n = n+1
여기서 dequeue는 큐에서 자료를 제거하는 것이므로 pop에 대응, enqueue는 큐에 자료를 삽입하는 것이므로 push에 대응한다. 또한 가장 뒤에 있는 요소를 반환하는 back이 없으므로 이를 추가해주면 될 듯 하다.
front와 rear를 굳이 mod N으로 해주는 이유는, front나 back의 위치가 큐의 배열의 크기(N)를 넘어가면 안되므로 다시 처음으로 돌아가기 위함이다.
명령어 입력
이 문제 역시 명령어를 입력하여 정수만을 저장할 수 있으면 되는 것이므로, 명령어 입력에 대해 대략 수도코드를 짜보았다.
int n 선언
문자열 command 선언
Queue q 선언
n 입력받음
for i=0, i<n, i++
cmd 입력받음
if cmd = size then
q.size() 출력
else if cmd = empty then
q.empty() 출력
else if cmd = front then
q.front() 출력
else if cmd = back then
q.front() 출력
else if cmd = push then
int x 선언하고 입력받기
q.push() 실행
else if cmd = pop then
q.pop() 출력
스택(Stack)은 후입선출(Last-in first-out, LIFO) 방식으로 자료를 삽입하거나 제거할 수 있는 자료구조 중 하나이다.
이번 문제는 이 스택을 구현하고 이를 명령어로 실행하는 것을 요구한다.
출처: 위키백과
구현해야 하는 명령 다섯가지
push X: 정수 X를 스택에 넣는 연산이다.
pop: 스택에서 가장 위에 있는 정수를 빼고, 그 수를 출력한다. 만약 스택에 들어있는 정수가 없는 경우에는 -1을 출력한다.
size: 스택에 들어있는 정수의 개수를 출력한다.
empty: 스택이 비어있으면 1, 아니면 0을 출력한다.
top: 스택의 가장 위에 있는 정수를 출력한다. 만약 스택에 들어있는 정수가 없는 경우에는 -1을 출력한다.
아이디어/참고
스택의 추상 자료형(ADT)은 다음과 같다. (출처: Data Structures & Algorithms in C++, 2nd Edition)
Algorithm size():
return t+1
Algorithm empty():
return (t<0)
Algorithm top():
if empty() then
throw StackEmpty exception
return S[t]
Algorithm push(e):
if size() = N then
throw StackFull exception
t←t+1
S[t]←e
Algorithm pop():
if empty() then
throw StackEmpty exception
t←t−1
이를 클래스로 만들면 될 것 같다. 그리고 해당 문제는 정수만 구현하면 된다.
명령어 입력
이 문제는 단순 스택의 함수를 호출하는 것이 아닌 명령어가 입력으로 주어지면 호출하는 방식이므로, 명령어를 받아들이고 조건문을 통하여 명령어가 맞으면 해당 명령을 실행하는 식으로 코드를 짜면 될 것 같다.
int n 선언
string command 선언
Stack s 선언
n 입력받음
for i=0, i<n, i++
cmd 입력받음
if cmd = size then
s.size() 출력
else if cmd = empty then
s.empty() 출력
else if cmd = top then
s.top() 출력
else if cmd = push then
int x 선언하고 입력받기
s.push() 실행
else if cmd = pop then
s.pop() 출력
#include <iostream>
#include <string>
using namespace std;
#define CAPACITY 1000
class CustomStack {
private:
int* stack_array;
int capacity;
int t;
public:
CustomStack(int cap){
stack_array = new int[cap];
capacity = cap;
t = -1;
}
int size() const{
return (t+1);
}
int empty() const{
if (t<0)
return 1;
else
return 0;
}
int top() const{
if (empty() == 1) return -1;
return stack_array[t];
}
void push(int x){
t++;
stack_array[t] = x;
}
int pop(){
if (empty() == 1) return -1;
int temp = stack_array[t];
t--;
return temp;
}
};
int main()
{
int n;
string cmd;
CustomStack s(CAPACITY);
cin >> n;
for (int i=0; i<n; i++){
cin >> cmd;
if (cmd == "size"){
cout << s.size() << '\n';
}
else if (cmd == "empty"){
cout << s.empty() << '\n';
}
else if (cmd == "top"){
cout << s.top() << '\n';
}
else if (cmd == "push"){
int x;
cin >> x;
s.push(x);
}
else if (cmd == "pop"){
cout << s.pop() << '\n';
}
}
return 0;
}
두 번째 답안
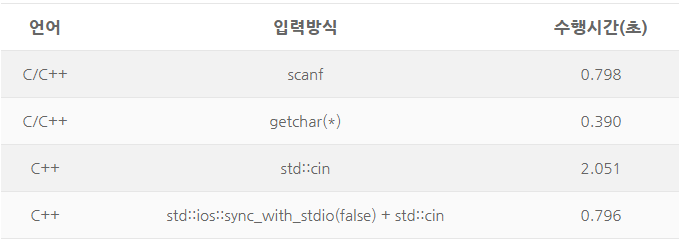
- 문제를 풀다보니 실행시간이 312ms나 나올 게 있나..? 하는 생각이 들어서 찾아봤더니, std::cin과 std::cout이 printf와 scanf보다 속도가 엄청 느리다는 이야기가 있었다. 다른 사람들이 C++로 작성한 것을 참고해보니 전부 printf와 scanf를 사용하였다.
(0, 0) 좌표에서 입력받은 값 n의 2승(=n^2) 부터 시작하여 행(row)의 값이 증가하는 방향으로 시작
테스트 환경
- OS: Windows 10
- IDE: Visual Studio Code
- 컴파일러: Visual C++
첫 번째 답
- 코드 용량: 1988KB
- 실행 시간: 156ms
- 아이디어
실행 순서
- 답안
#include <iostream>
using namespace std;
void snail(int n, int find)
{
int l = n;
int value = n * n;
int row = -1;
int col = 0;
int dir = 1;
int x, y;
int** arr;
arr = new int* [n];
for(int i=0; i<n; i++) arr[i] = new int[n];
while (l > 0){
for (int i=0; i<l; i++){
row = row + dir;
arr[row][col] = value;
if (value == find){
x = col + 1;
y = row + 1;
}
value--;
}
l--;
for (int i=0; i<l; i++){
col = col + dir;
arr[row][col] = value;
if (value == find){
x = col + 1;
y = row + 1;
}
value--;
}
dir = dir * (-1);
}
for(int i=0; i<n * n; i++){
int r = i / n;
int c = i % n;
cout << arr[r][c] << " ";
if((i % n) == n - 1) cout << endl;
}
cout << y << " " << x << endl;
for(int i=0; i<n; i++) delete[] arr[i];
delete[] arr;
}
int main()
{
int n, find;
cin >> n >> find;
snail(n, find);
return 0;
}
두 번째 답
첫 번째 코드의 경우 아이디어를 따왔던 게시글에 있는 코드와 유사하게 짰음.
이번엔 꼭지점에 도달할 경우 방향을 바꾸는 방식으로 진행.
- 코드 용량: 1988KB
- 실행 시간: 156ms
- 아이디어
첫 열에 대해 값 입력.꼭지점에 도달하고, 두 번째 열이 첫번째가 되도록 함.꼭지점에 도달하고, 네 번째 행이 마지막이 되도록 함.
- 답안
#include <iostream>
using namespace std;
void snail(int n, int find)
{
int row = 0, col = 0;
int value = n*n;
int rfirst = 0, cfirst = 0;
int rlast = n-1, clast = n-1;
int x, y;
int** arr;
arr = new int* [n];
for(int i=0; i<n; i++) arr[i] = new int[n];
while (value > 0){
arr[row][col] = value;
if (value == find){
x = col + 1;
y = row + 1;
}
value--;
if (row < rlast && col == cfirst){
row++;
if (row == rlast) cfirst++;
}
else if (row == rlast && col < clast){
col++;
if (col == clast) rlast--;
}
else if (row > rfirst && col == clast){
row--;
if (row == rfirst) clast--;
}
else if (row == rfirst && col > cfirst){
col--;
if (col == cfirst) rfirst++;
}
}
for(int i=0; i<n * n; i++){
int r = i / n;
int c = i % n;
cout << arr[r][c] << " ";
if((i % n) == n - 1) cout << endl;
}
cout << y << " " << x << endl;
for(int i=0; i<n; i++) delete[] arr[i];
delete[] arr;
}
int main()
{
int n, find;
cin >> n >> find;
snail(n, find);
return 0;
}
#include <string>
#include <iostream>
using namespace std;
bool isGroupWord(string str) {
int i = 0;
while (i < str.length() - 1) {
// 인접한 두 문자가 같은 문자일 경우 스킵
if (str.at(i) == str.at(i + 1)) {
i++;
} else {
for (int j = i + 1; j < str.length(); j++) {
// 연속해서 나타나지 않는 경우 false 반환
if (str.at(i) == str.at(j))
return false;
}
i++;
}
}
return true;
}
int main() {
int n, count;
string* str;
// 단어 개수 입력받고 str에 배열 동적할당
cin >> n;
str = new string[n];
// 단어 입력
for (int i = 0; i < n; i++) {
cin >> str[i];
}
count = 0;
// 단어가 그룹 단어이면 count를 1 증가시킴
for (int i = 0; i < n; i++) {
if (isGroupWord(str[i])) count++;
}
cout << count << endl;
delete[] str;
return 0;
}
시간복잡도를 최적화한 풀이
- 이미 등장한 알파벳인지를 판단하는 불 타입 배열 선언
- 제출한 답: C++로 작성, 1988KB
- 결과: 정답
#include <string>
#include <iostream>
using namespace std;
const char LITTLE_A = 'a';
bool isGroupWord(string str) {
// 단어 중복을 체크할 불 배열 선언
bool* wordCheck = new bool[26]{ false, };
wordCheck[str.at(0) - LITTLE_A] = true;
for (int i = 1; i < str.length(); i++) {
// 이미 등장한 알파벳인지 체크
if (!wordCheck[str.at(i) - LITTLE_A])
wordCheck[str.at(i) - LITTLE_A] = true;
// 만약 이미 등장한 알파벳이라면 앞자리의 알파벳과 동일한지 체크
else
if (str.at(i) != str.at(i - 1)) return false;
}
delete[] wordCheck;
return true;
}
int main() {
int n, count;
string* str;
// 단어 개수 입력받고 str에 배열 동적할당
cin >> n;
str = new string[n];
// 단어 입력
for (int i = 0; i < n; i++) {
cin >> str[i];
}
count = 0;
// 단어가 그룹 단어이면 count를 1 증가시킴
for (int i = 0; i < n; i++) {
if (isGroupWord(str[i])) count++;
}
cout << count << endl;
delete[] str;
return 0;
}
#include <iostream>
using namespace std;
void swap(int &a, int &b) {
int temp;
temp = a;
a = b;
b = temp;
}
void sort(int *arr, int n) {
int min;
for (int i = 0; i < n - 1; i++) {
min = i;
for (int j = i; j < n; j++) {
if (arr[j] < arr[min]) {
min = j;
}
};
swap(arr[i], arr[min]);
}
}
int main() {
int n, *arr;
cin >> n;
arr = new int[n];
for (int i = 0; i < n; i++) {
cin >> arr[i];
}
sort(arr, n);
for (int i = 0; i < n; i++) {
cout << arr[i] << endl;
}
delete[] arr;
return 0;
}